принтер
35 коммент.
Задача: установка принтера в Linux и печать в Linux с помощью CUPS, выводить на печать документы через локально подключённые принтеры.
Читать далее
Решение: требуется установить систему печати CUPS и добавить принтер, на что требуется не больше минуты - после этого принтер в Linux будет печатать.
Няня, где же кружка... или Ставим CUPS
На самом деле CUPS [?] с кружками и спиртным он ничего общего не имеет. Перед тем, как его ставить, хорошо бы посмотреть на поддержку ваших принтеров. Если с поддержкой полный порядок, ставим следующие пакеты:
Кстати, весьма распространённая ошибка: ставят только cupsys, или забывают foo2zjs, в результате чего при отправке задания на печать из принтера ничего не вылезает, а в логах вот такие записи:
В печать!
Подключаем принтер к компьютеру. Например, если у вас принтер с подключением по USB, о подключении можно узнать командой lsusb вот так:
Страница CUPS может долго загружаться, если указаны много других сетевых подключений или неправильно настроен DNS. Если машина локальная, и CUPS очень долго загружается, попробуйте на время вырубить сетевой интерфейс
Далее пишем имя принтера, на латинице и без пробелов:
Выбираем драйвер для своей модели принтера:
Далее определяемся со способом подключения принтера, в моём случае (USB-шный принтер) соответственно:
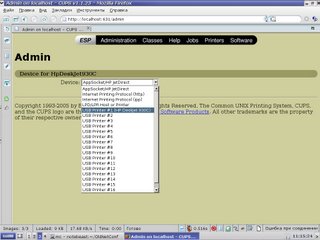
Ещё пара кликов - и всё готово, теперь принтер установлен и настроен. Если теперь зайти в Printers, он появится и доложит о своей готовности к печати:
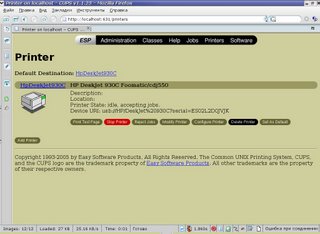
Соответствующими кнопками можно настроить доступные параметры печати: разрешение, размер бумаги и прочее. Всё, после этого принтер у вас появится в пользовательских приложениях. Например, в ОпенОфисе - и на него можно сразу чего-нибудь напечатать.
Печать из GiMP
Для этого потребуется установить ещё несколько пакетов и пожертвовать несколько мегабайт дискового пространства:
Тут есть одни грабельки: по умолчанию gimp-print полагает, что ваш принтер сто пудов postscript-совместимый, что, конечно же, далеко не всегда так. Поэтому не спешите радостно печатать фотографии, иначе вместо них из принтера может поползти многостраничная греко-латинско-французская ересь вместо изображения. Для того, чтобы это не произошло, указываем gimp-print наш принтер явно:
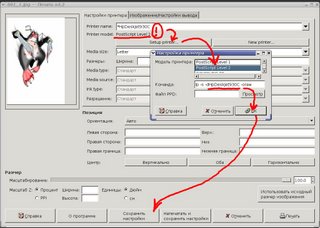
То есть жмём "Настроить принтер", выбираем модель принтера, подтверждаем и сохраняем настройки. Теперь всё должно пойти нормально.
Ссылки
Признаться, когда я ещё на Debian Woody настраивал принтер в Linux, я удивлялся руководствам в сети на эту тему (да-да, я читал руководства, поставляющиеся с CUPS, но читать их стоит после того, как всё работает). Либо это решение уж слишком конкретной проблемы, либо попытка объять необъятное и в итоге мануал ни о чём. Есть общее руководство по установке принтеров, но оно жутко устарело, а это, хотя и свежее, но обзорное. Неплохое руководство здесь и у меня по настройке печати через Samba. Очень хороший перевод документации к CUPS тут, о настройке можно ещё почитать здесь. О поддержке принтеров в Linux можно узнать на официальном сайте CUPS.
Няня, где же кружка... или Ставим CUPS
На самом деле CUPS [?] с кружками и спиртным он ничего общего не имеет. Перед тем, как его ставить, хорошо бы посмотреть на поддержку ваших принтеров. Если с поддержкой полный порядок, ставим следующие пакеты:
aptitude install cupsys gs-esp foomatic-bin foo2zjs cups-pdfвместе со всеми зависимостями. Последний пакет, cups-pdf, добавляет возможность печатать сразу в PDF из любой программы в Linux. Важно поставить не только сам CUPS, но и программы, которые он использует, имеющие не вполне очевидные названия.
Кстати, весьма распространённая ошибка: ставят только cupsys, или забывают foo2zjs, в результате чего при отправке задания на печать из принтера ничего не вылезает, а в логах вот такие записи:
I [23/Aug/2005:14:41:46 +0400] Adding end banner page "none" to job 7.Это может отхватить мегабайт 10-20, смотря сколько и чего уже поставлено в системе. Всё поставится, распакуется и настроится - теперь осталось добавить принтер и начать печатать.
I [23/Aug/2005:14:41:46 +0400] Job 7 queued on 'HPDeskJet930C' by 'penta4'.
E [23/Aug/2005:14:41:46 +0400] Unable to convert file 0 to printable format for job 7!
I [23/Aug/2005:14:41:46 +0400] Hint: Do you have ESP Ghostscript installed?
I [23/Aug/2005:14:41:46 +0400] Hint: Try setting the LogLevel to "debug".
В печать!
Подключаем принтер к компьютеру. Например, если у вас принтер с подключением по USB, о подключении можно узнать командой lsusb вот так:
root@dot:/dev# lsusbПринтер в Linux себя проявит вот так:
Bus 008 Device 003: ID 04e8:3272 Samsung Electronics Co., LtdВ данном случае воткнут принтер Samsung CP-300. Чтобы добавить новый принтер или менять опции уже установленного, запускаем любой броузер и в адресной строке набираем:
Bus 008 Device 001: ID 1d6b:0002 Linux Foundation 2.0 root hub
Bus 007 Device 001: ID 1d6b:0001 Linux Foundation 1.1 root hub
Bus 006 Device 001: ID 1d6b:0001 Linux Foundation 1.1 root hub
Bus 005 Device 002: ID 046d:c52f Logitech, Inc.
Bus 005 Device 001: ID 1d6b:0001 Linux Foundation 1.1 root hub
Bus 004 Device 001: ID 1d6b:0002 Linux Foundation 2.0 root hub
Bus 003 Device 001: ID 1d6b:0001 Linux Foundation 1.1 root hub
Bus 002 Device 001: ID 1d6b:0001 Linux Foundation 1.1 root hub
Bus 001 Device 001: ID 1d6b:0001 Linux Foundation 1.1 root hub
http://localhost:631Должна должна появиться страница с настройками принтеров в Linux, что-то вроде показанного на скриншоте:
 |
| From Записки дебианщика [beta] |
Страница CUPS может долго загружаться, если указаны много других сетевых подключений или неправильно настроен DNS. Если машина локальная, и CUPS очень долго загружается, попробуйте на время вырубить сетевой интерфейс
ifconfig eth0 downНапример, как я подключал свой принтер HP DeskJet 930C в CUPS на Debian 3.1 Sarge. Нажимаем Find New Printers - CUPS должна найти наш принтер и скорее всего найдёт его. Если же принтеров нет, CUPS так об этом и скажет, No Printers - тогда можно нажать на Add printer. Но нам повезло и принтеры нашлись:
 |
| From Записки дебианщика [beta] |
Далее пишем имя принтера, на латинице и без пробелов:
 |
| From Записки дебианщика [beta] |
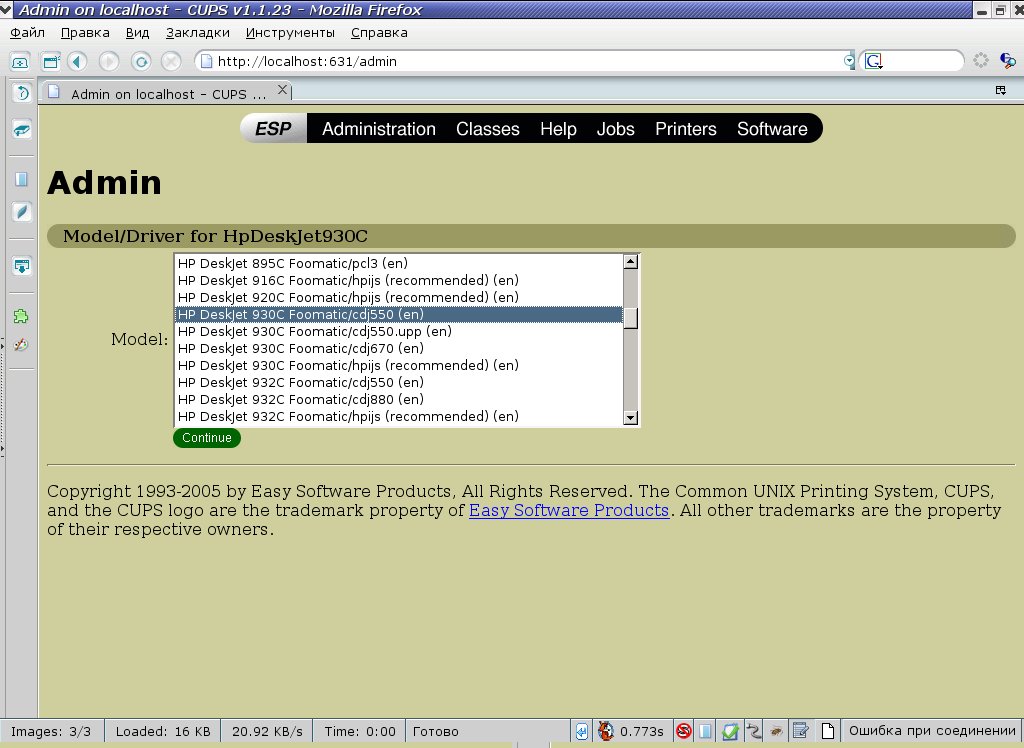
Выбираем драйвер для своей модели принтера:
 |
| From Записки дебианщика [beta] |
Далее определяемся со способом подключения принтера, в моём случае (USB-шный принтер) соответственно:

Ещё пара кликов - и всё готово, теперь принтер установлен и настроен. Если теперь зайти в Printers, он появится и доложит о своей готовности к печати:
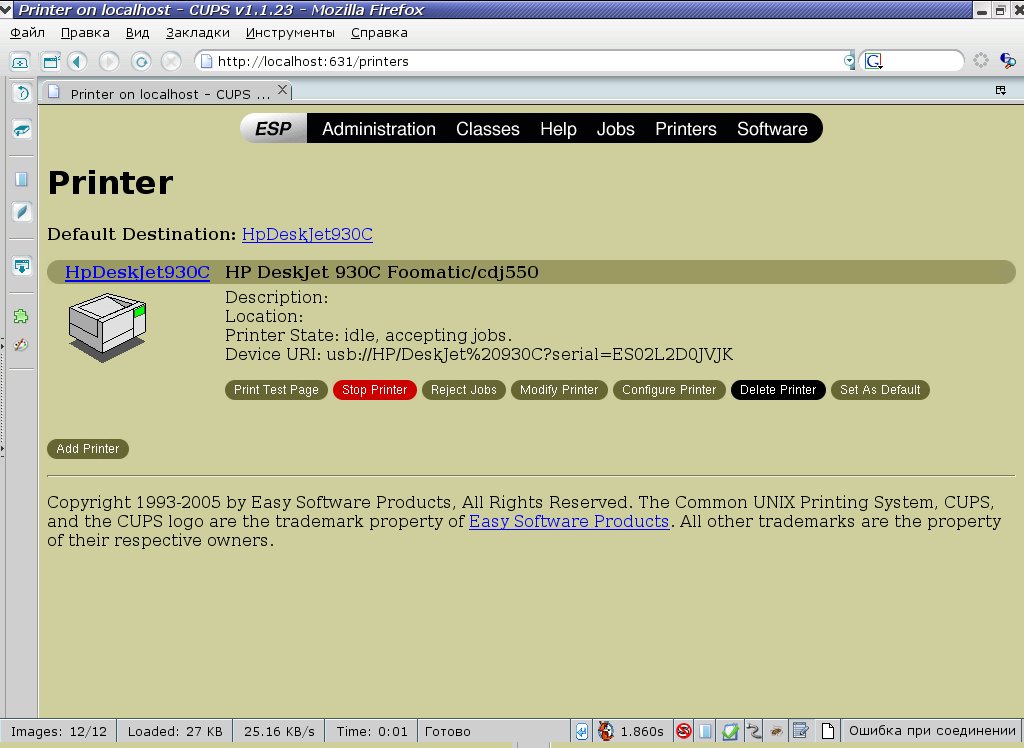
Соответствующими кнопками можно настроить доступные параметры печати: разрешение, размер бумаги и прочее. Всё, после этого принтер у вас появится в пользовательских приложениях. Например, в ОпенОфисе - и на него можно сразу чего-нибудь напечатать.
Печать из GiMP
Для этого потребуется установить ещё несколько пакетов и пожертвовать несколько мегабайт дискового пространства:
aptitude install cupsys-driver-gimpprint gimp-printпоставится и настроится. Теперь запускаем GiMP, открываем любое изображение и жмём Файл - Печать. После этого появится солидных размеров диалог, в котором можно настроить что угодно, относящееся к печати изображений.
Тут есть одни грабельки: по умолчанию gimp-print полагает, что ваш принтер сто пудов postscript-совместимый, что, конечно же, далеко не всегда так. Поэтому не спешите радостно печатать фотографии, иначе вместо них из принтера может поползти многостраничная греко-латинско-французская ересь вместо изображения. Для того, чтобы это не произошло, указываем gimp-print наш принтер явно:

То есть жмём "Настроить принтер", выбираем модель принтера, подтверждаем и сохраняем настройки. Теперь всё должно пойти нормально.
Ссылки
Признаться, когда я ещё на Debian Woody настраивал принтер в Linux, я удивлялся руководствам в сети на эту тему (да-да, я читал руководства, поставляющиеся с CUPS, но читать их стоит после того, как всё работает). Либо это решение уж слишком конкретной проблемы, либо попытка объять необъятное и в итоге мануал ни о чём. Есть общее руководство по установке принтеров, но оно жутко устарело, а это, хотя и свежее, но обзорное. Неплохое руководство здесь и у меня по настройке печати через Samba. Очень хороший перевод документации к CUPS тут, о настройке можно ещё почитать здесь. О поддержке принтеров в Linux можно узнать на официальном сайте CUPS.











{kind=link}